Lab 連結:Lab: Copy-on-Write Fork for xv6
題目解析
The problem
The fork() system call in xv6 copies all of the parent process’s user-space memory into the child. If the parent is large, copying can take a long time. Worse, the work is often largely wasted: fork() is commonly followed by exec() in the child, which discards the copied memory, usually without using most of it. On the other hand, if both parent and child use a copied page, and one or both writes it, the copy is truly needed.
在現在的 xv6 設計中,fork() 出來的 child 會複製 parent 的所有 memory,但是在很多時候,child 會直接接著執行 exec(),也就直接把先前的一大票 memory 覆蓋掉了,這讓當 memory 的複製便得很浪費。
想要節省這樣的浪費可以在 fork() 的時候只複製一份 page table 給 child,但是這麼做的話,每當 parent or child 想要 write 的時候,就會需要真的 copy 一份才行
The solution
Your goal in implementing copy-on-write (COW) fork() is to defer allocating and copying physical memory pages until the copies are actually needed, if ever.
這個 lab 要我們實做一個 copy-on-write (COW) fork() 的技術,跟先前提到的一樣,只有在「真的需要的時候」才真的複製一個 page 出來。
COW
fork()creates just a pagetable for the child, with PTEs for user memory pointing to the parent’s physical pages. COWfork()marks all the user PTEs in both parent and child as read-only. When either process tries to write one of these COW pages, the CPU will force a page fault. The kernel page-fault handler detects this case, allocates a page of physical memory for the faulting process, copies the original page into the new page, and modifies the relevant PTE in the faulting process to refer to the new page, this time with the PTE marked writeable. When the page fault handler returns, the user process will be able to write its copy of the page.
實際的作法是把 child 的 pagetable 跟 parent 的一樣指向同樣的 physical memory 區域,並且都 mark 為 read only,當有 process 想要 write 的時候,就會進入到 page fault 處理,page fault 會複製出一份可以 write 的 page
Here’s a reasonable plan of attack.
- Modify
uvmcopy()to map the parent’s physical pages into the child, instead of allocating new pages. ClearPTE_Win the PTEs of both child and parent for pages that havePTE_Wset.
在 uvmcopy() 中執行複製 pagetable 並且設定 PTE_W 的計畫
uvmcopy()的使用時機也只有fork()的時候會用到
- Modify
usertrap()to recognize page faults. When a write page-fault occurs on a COW page that was originally writeable, allocate a new page withkalloc(), copy the old page to the new page, and install the new page in the PTE withPTE_Wset. Pages that were originally read-only (not mappedPTE_W, like pages in the text segment) should remain read-only and shared between parent and child; a process that tries to write such a page should be killed.
在 (write to read only) page fault 時,會進入到 usertrap() 處理,這時候會分為一下兩種情況:
- 這個 page 在最初的時候,是
PTE_W(在這個情況下才需要 Copy-on-Write) - 這個 page 在最初的時候,是本來就不是
PTE_W: 這是真正的 page fault, kill the process- 像是 text segment (instructions 的區域)
- 這裡就需要考慮一下該把最初
PTE_W存放在哪裡了
- Ensure that each physical page is freed when the last PTE reference to it goes away – but not before. A good way to do this is to keep, for each physical page, a “reference count” of the number of user page tables that refer to that page. Set a page’s reference count to one when
kalloc()allocates it. Increment a page’s reference count when fork causes a child to share the page, and decrement a page’s count each time any process drops the page from its page table.kfree()should only place a page back on the free list if its reference count is zero. It’s OK to to keep these counts in a fixed-size array of integers. You’ll have to work out a scheme for how to index the array and how to choose its size. For example, you could index the array with the page’s physical address divided by4096, and give the array a number of elements equal to highest physical address of any page placed on the free list bykinit()inkalloc.c. Feel free to modifykalloc.c(e.g.,kalloc()andkfree()) to maintain the reference counts.
這裡是在探討把 physical page free 掉的時機,「沒有任何 process 使用」時才真的 free 掉,雖然概念上很清楚的知道是這個時機,但其實要實做出來也沒有那麼容易。
- 每當
kalloc()之後,就給這個 page 一個 reference count kalloc()的時候,reference count 設定為 1- Increase: 因為
fork()產生出 child 的時候 - Decrease: 一個 process drop 這個 page 的時候
kfree()只有在 reference count 減少到 0 時才會真的把 page 放回 free list 中- 計算 reference count 的 data structure 可以是放在一個 fixed size 的 array 中
- 需要多大?
- 如何做 index 的 mapping?
- 要放在哪裡?(於
kinit()中放置這個 array)- 學習 free list 的初始化過程
- Modify
copyout()to use the same scheme as page faults when it encounters a COW page.
在 copyout() 的時候,也需要判斷有沒有遇到 COW page,如果是 COW page, 就比照辦理
- 這裡可以發現跟 Lazy allocation 的時候一樣,在 supervisor mode 的時候因為不會進入
usertrap()所以要自行處理。
- It may be useful to have a way to record, for each PTE, whether it is a COW mapping. You can use the RSW (reserved for software) bits in the RISC-V PTE for this.
可以在每個 PTE 中新增像是 PTE_C 去紀錄這是不是一個 COW mapping
- 其實有一點想要把原本的所有狀態都塞進去,
usertests -qexplores scenarios thatcowtestdoes not test, so don’t forget to check that all tests pass for both.
- Some helpful macros and definitions for page table flags are at the end of
kernel/riscv.h.
- If a COW page fault occurs and there’s no free memory, the process should be killed.
- 如果沒有free memory 時,就直接 kill the process
fork() 的當下
其實我覺得與其說是 fork() 時複製出一個 “read-only” 的 page table,不如說他是 “cannot-be-write” 會比較貼切,這麼說是因為 “要 write 的時候必須特別處理” 才是 copy-on-write 的核心,變成 read-only 並不那麼精確,另外,把他們一律視為 read-only 會有兩個壞處:
- “原本的 page 是否能 read” 這個資訊被洗掉了
- “原本的 page 是否能 write” 這個資訊被洗掉了
所以我這裡的策略到不是把所有 PTE 都變成 read-only 這裡的策略是
- 把所有的
PTE_W == 0 - 把原本的
PTE_W的資訊放在PTE_RES - 設定
PTE_COW
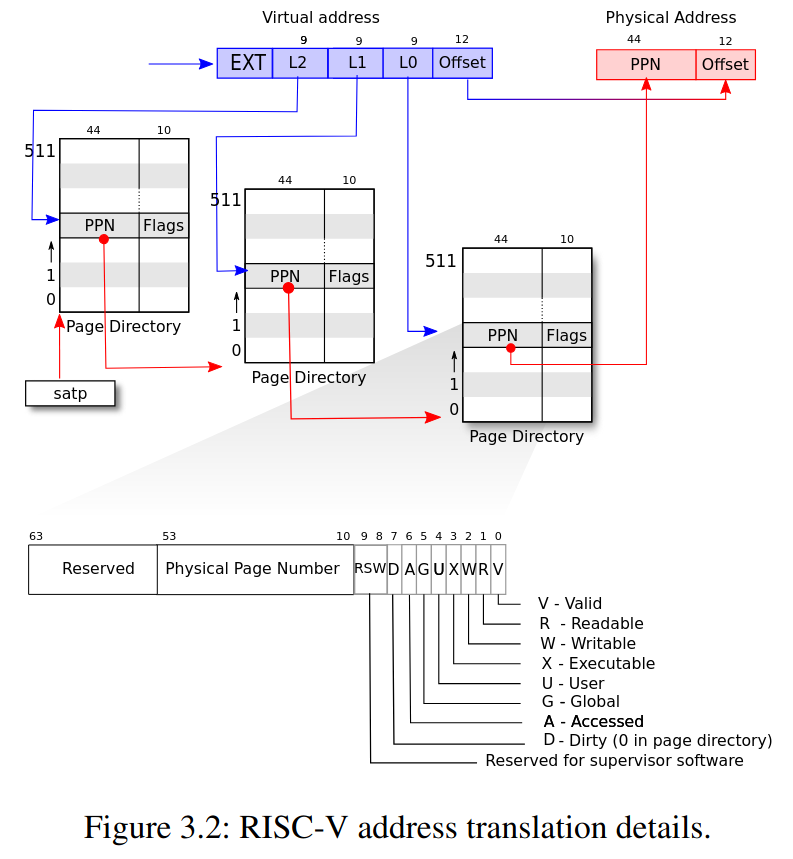
這時候可以利用 RSW 的 bit 8, 9 資訊紀錄
kernel/riscv.h
#define PTE_V (1L << 0) // valid
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // user can access
#define PTE_COW (1L << 8) // is COW page
#define PTE_COW_W (1L << 9) // PET_W before becomming COW
uvmcopy()
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
if((mem = kalloc()) == 0)
goto err;
memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
改成下面這樣:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// parent pte
// set PTE_COW and PTE_COW_W
*pte |= PTE_COW; // set PTE_COW
if (*pte & PTE_W)
*pte |= PTE_COW_W; // set PTE_COW_W
*pte &= ~PTE_W; // cannot be wite
// child pte
flags = PTE_FLAGS(*pte); // as same as parent
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
Reference Count
有多少 page 需要 Reference Count
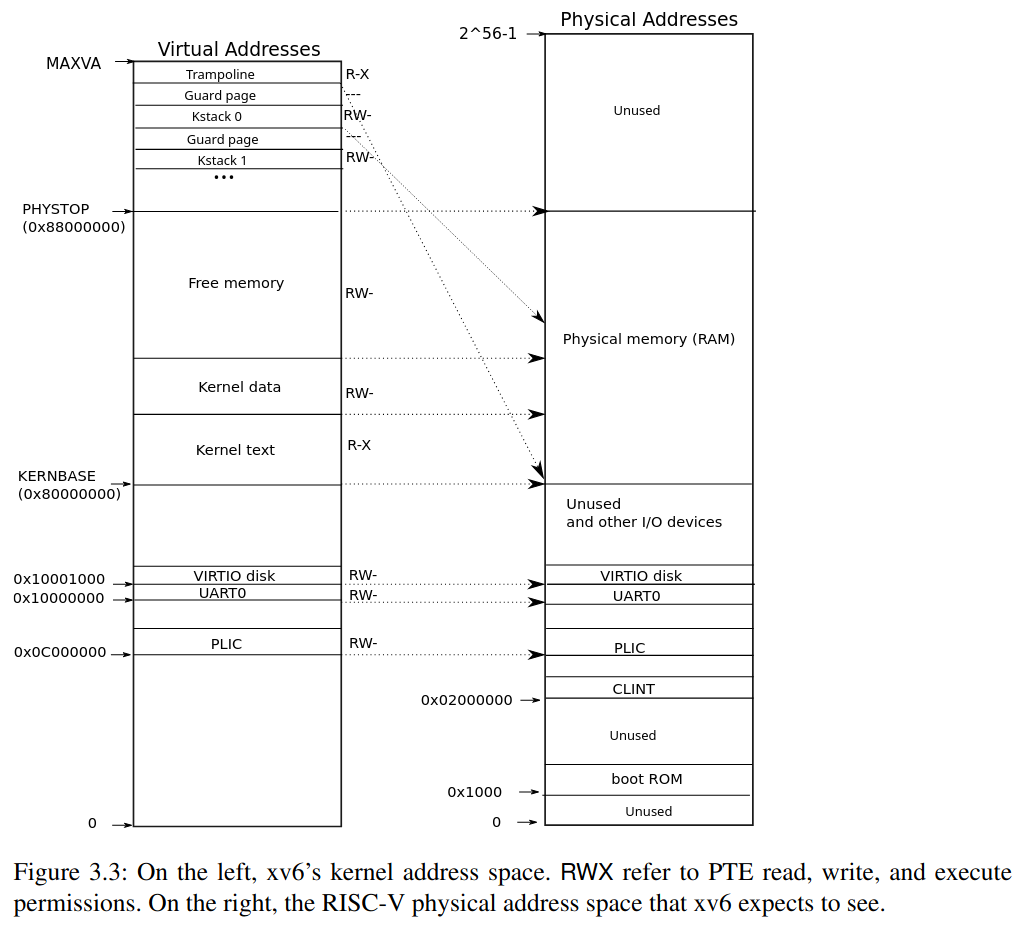
// the kernel expects there to be RAM
// for use by the kernel and user pages
// from physical address 0x80000000 to PHYSTOP.
#define KERNBASE 0x80000000L
#define PHYSTOP (KERNBASE + 128*1024*1024)
Physical memory (RAM) 的 address 為 KERNBASE ~ PHYSTOP
-> 0x80000000 ~ 0x88000000
在 Physical memory (RAM) 又因為 kernel text 與 kernel data 佔去了一部分
實際上 user program 會用到的只有 end ~ PHYSTOP
kernel/kalloc.c
extern char end[]; // first address after kernel.
// defined by kernel.ld.
void
kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
// 注意這裡,最後一個可用的 page
// 是 starting address == PHYSTOP - PGSIZE
// 的那一個 page
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}
這裡需要小注意一下
PHYSTOP是不包含的end則不一定,要看PGROUNDUP()的結果 (因為不可以跟 kerenl 塞在同一個 page 中)
可用的 RAM 的範圍:
最開始的 page
KERNBASE: 0x80000000 作為開頭的這個 page- physical address:
0x80000000 ~ 0x80000fff 0x80000xxx的 address 都屬於最開頭的 page0x80000xxx的 address 會共用同一個 reference countPGROUNDDOWN(pa) == 0x80000000的pa會共用同一個 reference count (index == 0)
最後一個 page
PHYSTOP - PGSIZE == 0x88000000 == 0x87fff000作為開頭的這個 page- physical address:
0x87fff000 ~ 0x87ffffff 0x87fffxxx的 address 都屬於最開頭的 page0x87fffxxx的 address 會共用同一個 reference countPGROUNDDOWN(pa) == 0x87fffxxx的pa會共用同一個 reference count,並且是最後一個 index
需要 reference count 的 page 數量為
題目說可以用一個 fix-sized 的 array 就好,言下之意就是雖然 kernel text 與 kernel data 雖然實際上部需要 reference count 的管理,但還是給它們 refrence count 單純為了求一個方便
需要 index 的數量為
087fff - 0x80000 + 1 = 0x08000088000 - 0x80000 = 0x08000(PHYSTOP - KERNBASE) / PGSIZE = 0x08000
index 的方法
address condition calculate index index
-----------------------------------------------------------------------
0x87fffxxx | PGROUNDOWN(pa) == 0x87fff 000 | 0x87fff - 0x80000 == 0x07fff
0x87ffexxx | PGROUNDOWN(pa) == 0x87ffe 000 | 0x87ffe - 0x80000 == 0x07ffe
. | |
. | |
. | |
0x80001xxx | PGROUNDOWN(pa) == 0x80001 000 | 0x80001 - 0x80000 == 0x00001
0x80000xxx | PGROUNDOWN(pa) == 0x80000 000 | 0x80000 - 0x80000 == 0x00000
如果有了 physical address pa, 它在 array of reference count 的 index 計算公式為:
index = (PGROUNDOWN(pa) >> 12) - 0x80000
也就是因為當初的
index = (PGROUNDOWN(pa) >> 12) - (KERNBASE >> 12)
等等會用一個 macro 來處理
Reference Count 的 Data Structure
存放位置
- 這個 array 最終實際上的位置會在 kernel data 的區域中
- 把 index 的作法寫成 macro 比較方便
kernel/kalloc.c: 跟kmem一樣要使用spinlock
struct {
struct spinlock lock;
struct run *freelist;
int count[(PHYSTOP - KERNBASE) / PGSIZE];
} refcnt;
#define REFCNT(pa) refcnt.count[(PGROUNDDOWN(pa) >> 12) - (KERNBASE >> 12)];
Reference Count 的 Increament/Decreament
初始為 1 時
kalloc()
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r) {
kmem.freelist = r->next;
acquire(&refcnt.lock);
REFCNT((uint64) r) = 1;
release(&refcnt.lock);
}
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
Increament
fork()所導致的uvmcopy()時,要加一不過
uvmcopy()在kernel/vm.c中,refcnt所在的kernel/kalloc.c會需要提供一個 functionkernel/kalloc.c: inc_refcnt()
void
inc_refcnt(uint64 pa)
{
acquire(&refcnt.lock);
REFCNT((uint64) r)++;
release(&refcnt.lock);
}
kernel/vm.c: uvmcopy(): 使用inc_refcnt()
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// 1. Parent pte
// set PTE_COW and PTE_COW_W
*pte = *pte | PTE_COW; // set PTE_COW
if (*pte & PTE_W)
*pte = *pte | PTE_COW_W; // set PTE_COW_W
*pte = *pte & ~PTE_W; // cannot be wite
// 2. Child pte
flags = PTE_FLAGS(*pte); // as same as parent
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
kfree(mem);
goto err;
}
inc_refcnt(pa); // <-- increase reference count when fork
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
Decreament
kernel/kalloc.c: kfree()
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
acquire(&refcnt.lock);
REFCNT(pa)--;
release(&refcnt.lock);
if (REFCNT(pa) > 0)
return;
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
只有 reference count 減少到 0 時才會真的 free 掉這個 page
Page Fault 的處理
scause= 12: Instruction page faultscause= 13: Load page faultscause= 15: Store/AMO page fault (copy on write 的情形)
這裡跟 Lazy allocation 的處理類似
kernel/trap.c: usertrap()
void
usertrap(void)
{
// ...
} else if((which_dev = devintr()) != 0){
// ok
} else if(r_scause() == 15 && uncopied_cow(p->pagetable, r_stval())){
if (cow_alloc(p->pagetable) < 0)
setkilled(p);
} else {
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
setkilled(p);
}
// ...
}
kernel/vm.c
int
uncopied_cow(pagetable_t pagetable, uint64 va)
{
if (va >= MAXVA)
return 0;
pte_t *pte;
if (pte = walk(pagetable, va, 0) == 0)
return 0;
if ((*pte & PTE_V) == 0)
return 0;
if ((*pte & PTE_U) == 0)
return 0;
if ((*pte & PTE_COW_W) == 0) // COW 之前的 PTE_W
return 0;
return (*pte & PTE_COW);
}
int
cow_alloc(pagetable_t pagetable, uint64 va)
{
pte_t *pte;
}
kernel 中的 Copy-on-Write 如何處理
這裡就有一點像是前面的 Lab: Lazy 也會遇到的問題,因為現在我們處理的範圍都只有 user program 產生的 page fault,如果是 supervisor mode 的情況下想要 write COW page 就需要當下在 supervisor mode 自行處理
這裡要考慮的是從 kernel 複製到 user program 可能會 write COW page 的 copyout() 這個 function
kernel/vm.c: copyout()
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
if (uncopied_cow(pagetable, va0))
if (cow_alloc(pagetable, va0) == -1)
return -1;
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
心得:
這個 Lab 錯在一些小地方似乎不太容易發現,覺得真的不確定的時候要使用 gdb 去確認會比較好, 不過這幾個 Lab 做下來覺得使用 gdb 的心態也蠻重要的,像是這兩種心態:
- 使用 gdb 檢查哪裡的 value 有錯誤,並且想辦法修正錯誤的 value
- 先了解背後的原理,並且用 gdb 驗證背後的原理有沒有正確的被執行
我自己的體感是 2. 會比較好一些,1. 則是會有一種被 gdb 拉著走的感覺,但是真的沒頭緒的時候,還是可以用 1. 做一個範圍上的線縮。
除錯過程中學到的一些方便的 gdb 使用方式
情境:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
// for debug
for(i = 0; i < sz; i += PGSIZE){
// printf("%x,", i / PGSIZE);
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if (i == 0x402f000 - 0 * PGSIZE)
printf("!!!*pte = %p\n", *pte);
if((*pte & PTE_V) == 0) {
printf("*pte = %p\n", pte);
printf("i = %x\n", i);
printf("sz = %x\n", sz);
panic("uvmcopy: page not present");
}
}
for(i = 0; i < sz; i += PGSIZE){
// printf("%x,", i / PGSIZE);
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
// if (i == 0x402f000 - 0 * PGSIZE)
// printf("!!!*pte = %p\n", *pte);
if((*pte & PTE_V) == 0) {
printf("*pte = %p\n", *pte);
printf("i = %x\n", i);
printf("sz = %x\n", sz);
panic("uvmcopy: page not present");
}
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// parent pte
// set PTE_COW and PTE_COW_W
*pte |= PTE_COW; // set PTE_COW
if (*pte & PTE_W)
*pte |= PTE_COW_W; // set PTE_COW_W
*pte = *pte & ~PTE_W; // cannot be wite
// child pte
flags = PTE_FLAGS(*pte); // as same as parent
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
// kfree(mem);
goto err;
}
inc_refcnt(pa);
}
return 0;
err:
panic("uvmcopy: err");
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
發現觸發 panic("uvmcopy: page not present");
- set breakpoint
b kernel/vm.c: xxxatpanic("uvmcopy: page not present");- 發現
i == 0x402f000這個 iteration 的時候,會觸發panic("uvmcopy: page not present");
- 發現
再跑一次 gdb,這次先用
(gdb) add-symbol-file user/_cowtest
(gdb) b simpletest
(gdb) b *$stvec
(gdb) c
(gdb) b uvmcopy
(gdb) p watch(old, 0x42f000, 0)
$1 0x83f39178
知道受影響的 PTE 的 address 之後,在設定 watch point
(gdb) watch *(pte_t *) 0x83f39178
(gdb) c
這樣這一次就會知道是那裡更改了不該被更改的值
最後有發現是 macro 的 KERNBASE >> 12 寫成了 KERNBASE >> 3 一時疏忽忘記 HEX 中的三個 0 代表 12 個 bits